It's Valentine's Day
and
[Reply] |
The latest When I asked Jay what he saw in it, he said, "three houseflies forming a political party". I printed it out and brought it to Pam, who responded, "what's with the flies?". I told her that it was a VisualID. She trimmed it and hung it on the refrigerator. [Reply] |
I recently started hacking on tangoGPS: it's mostly pretty swell (which has made it the most popular GPS/mapping application on the FreeRunner) but there are a couple of things about it that just vex me: One thing is that, because the FreeRunner's amazingly high-resolution LCD is of an amazingly higher resolution than OpenStreetMap expects when they rasterise their map-tiles, labels (and a lot of other details) that would be perfectly legible on a 96-DPI desktop computer monitor are inscrutable on the FreeRunner's >280-DPI screen. So, I fixed that. Another thing is that it can be hard to make much sense out of the stock points-of-interest display. For example, here are a bunch of schools around the area where I grew up: 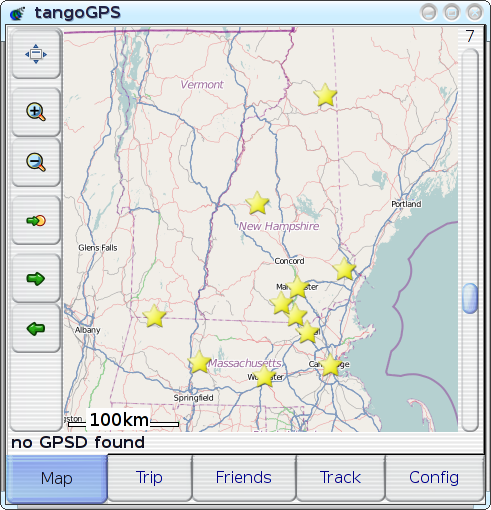
Plotted on this map are campuses for UNH, U-Mass, MIT, Souhegan High School, and a few other random items. It takes considerable conscious effort for me to figure out which is which, even though these are all places that I know (places that I marked on the map!). This display would be great as some sort of statistical scatter plot, but it's mostly useless as a tool for locating specific, individual points of interest: since all of the points look exactly the same, the only attribute that can be used to identify a point is its position, and there's often just not enough `cognitive resolution' to completely disambiguate solely by position--we often just don't think in that level of detail with regard to location, and there's often something akin to quantisation-error when we try. If you happen to be unfamiliar with this region or the schools that I've plotted, then you can immediately appreciate how problematic it can be to have positional cues be the only way to distinguish points: it's worse for unfamiliar territory, where either the region as a whole or the desired point within the region is just not familiar enough for any spatial cues to be useful by themselves. If you're at all familiar with the region depicted in the map, and where the points of interest are supposed to be, then you might expect it to be pretty easy to pick things out, but it turns out that it's actually quite hard to find or identify an individual point in a scatter plot even for `easy' datasets. On the above map, for example, there are very few points of interest, several of them have well-known locations, and no two points are colocated. In other words, this is an `easy' example, and things only get harder from here. The version that has markers for all of the places that are actually of interest to me (or anyone else, I imagine) is much worse. Throw in enough identical-looking `clutter' and anyone would find it virtually impossible to determine which of several closely-spaced points is the desired one. Unfamiliarity just changes the metric for `close', increasing the distance at which two things can remain indistinguishable. This whole situation actually sounds like exactly the same sort of problem-space that motivated the developent of VisualIDs in the first place. The problem was originally laid-out in terms of `scenery for data worlds', with datascapes as an analogue to actual landscapes; but what if the datascape in question turns out to relate somewhat more directly to an actual landscape--what if the `virtual landscape' over which the scenery-points or `landmarks' are strewn is actually a direct representation of an actual, physical landscape? There's something about that that's just perfect. So, I did it. And it was an impressively quick (and impressively clean)
modification--all I had to do was to generalise tangoGPS' POI-icon code
a little bit (adding And, after only some minor tweaks, I can say that it's a resounding success: in my own real-world experience over the past month or so since I actually implemented this and started using it, it's turned out to be a real boon, making tangoGPS' POI display significantly more useful--I've been able to use the POI display to quickly and easily identify travel-destinations before or while navigating to them, and it's also been quite helpful in showing other people where things are. I've even been able to add POIs for new and unfamiliar places just by inputting their lat/lon coordinates and then looking out for a new and unfamiliar icon--then, once I've seen it, it's trivial to find it again. The experience is just so much better that I'm completely unwilling to go back to life without VisualIDs. But pictures can be so much more illustrative, so here's a primer--a quick introduction to mapping with VisualIDs: pick one of these icons, take a loot at the icon and the associated place-name, just for about as long as it would take you to say `oh, that's an interesting icon for NAME' (as you might when you see it appear after recording your point of interest into your GPS):
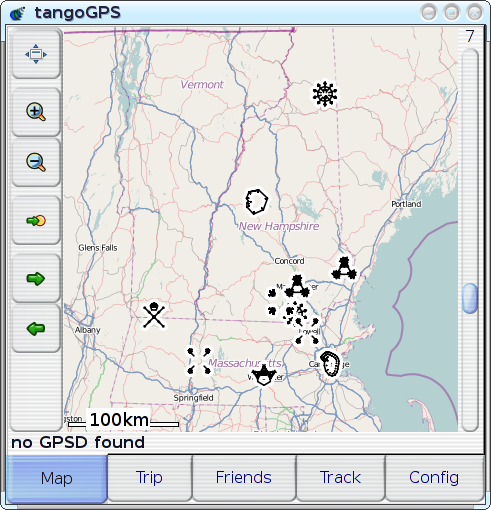
Now, try to to find:
It's even easy to find the `buried treasure' site, isn't it? So, it works! Though, I've yet to explain the `minor tweaks' mentioned above: while most of the glyph-types make perfectly legible cartographic icons, two of them (`line' and `path') are, unsurprisingly, often difficult to distinguish from the street-segments over which they are drawn--so I simply disabled them. Almost all of the other glyph-types are represented in this screenshot (`shape', `radial', `symmetry', `figure'; the only one that's missing, by sheer happenstance, is `spiral'), and they all work reasonably well; though one obvious issue is that the rendering of `symmetry' glyphs (as for Souhegan High School and U-Mass) may have potential to be confusing, so it may make sense to disable them too, if I can't find a way of rendering them such that the sub-glyphs are more clearly connected to each other. An interesting side-effect of using distinctive icons for POIs, actually relating back to the whole `map with scatterplot' concept: not only is it easier to recognise any single given POI, but multiple POIs are recognisable simultaneously, which causes the relationships between POIs to become apparent. For example: when I was, for the first time, able see all of my favorite places plotted on the map simultaneously and recognisably, it became clear that many things just weren't situated physically in the same way that I had organised them mentally--places that I'd always thought of as `close to each other' turned out to be physically further apart, vice versa, etc. In cases like those, the improvement in POI-recognition has been profound: where I would previously have had to spend time picking through numerous mistaken selections just because I'd started looking in the wrong place, I'm now able to immediately, correctly recognise and select the point that I want--even if it's not quite where I expected it to be. [Reply] |
Version 0.2 of my `applied mathematics and primitive
art' project,
There's some new functionality, and a new toy included, but the biggest change is that the internals have been completely refactored to use GObject. Restructuring everything around GObject has actually been really helpful in clearing up some points of confusion that I encountered during the initial implementation--now those semantic bugs have been squashed. Now that the big pieces of new architecture are in place, I can start shedding the old (and less usable) interfaces, I can start developing the finer points in the new interface, and I can start evolving the actual functionality to include things like:
(look for that stuff to start showing up in 0.3) The existing patches for Nautilus still work, for anyone who's using them (or who hasn't tried them but would like to). [From the NEWS file included in the tarball] Version 0.2.0 is a significant revision of libvisualid, though the
user-interface of the `mkvisualid' command remains mostly unaltered;
visible changes include:
* A new "--base-weight" option has been added, to set the default
weight for generators in the probability-set; it's possible to
disable all generators with "--base-weight=0" and then easily
enable only specific generators.
* A new "--autocache-dir" option has been added, allowing the
glyph-cache directory to be specified.
* The "--autocache" and "--output" options can now be used
simultaneously (in the future, the `autocache' files will be in
a different format capable of storing glyph-structures with all
attribute-data intact, instead of just storing renditions).
* If the path specified via the "--output" option exists and is a
directory, then a file is created in that directory with a name
according to the input name.
A new `VisualID Explorer' demo-application has been added, using GTK+ with
several alternate GUIs defined using Glade.
The libvisualid library contains several new features, including:
* visualid_complexity(), a function providing overall
complexity-metrics for VisualID glyphs.
* visualid_set_cachedir(), a function that allows the global
cache-directory to be changed.
* Automatic limiting of overall glyph-complexity: an integer in
constants.c (complexity_max) controls the maximum
glyph-complexity, having a default value of 5000 (a measure of
something akin to `number of brushstrokes').
* As the result of everything having been refactored using GObject
(cf. details below), we finally have a way to *deallocate*
VisualID glyph-structures!
* Some bugfixes.
This release of the libvisualid library is binary-incompatible from
all previous releases, and is source-incompatible in a few minor ways:
* exec_generator() has been renamed to visualid_draw_path().
* generate_child() has been split into two special-purpose functions:
- visualid_glyph_new(), for producing root glyphs,
- visualid_glyph_spawn(), for producing and assigning
subordinate glyphs.
* All of the class-specific generator-functions have been reworked
to have the same parameters as visualid_glyph_spawn().
Aside from the above changes, libvisualid should be source-compatible
in every meaningful way.
The `generator' structs have been converted into GObject classes,
including a base `VisualID_Glyph' class; the existing structs have
been preserved for the time being, but this marks the beginning of
API-redesign whereby terminology will be corrected and the API will be
reformed into something more fit for general consumption (e.g.: public
names put into a namespace).
The naming of the structs in 0.1.x as `*_generator' was somewhat
inappropriate, and due to some misinterpretation of some ambiguous
text in the essay: while the `*_generator' structs /are/ data
/related/ to generators, the `gen_*' function itself (not the data
that it produces) /is/ the generator. The term, "glyph", has been
chosen for the base-class in the VisualIDs `shape grammar' by analogy
with written-language grammar where `glyphs' of typography are
realisations of abstract `characters'; the `characters' of the
shape-grammar would then be the classes per se: `radial', `spiral',
`figure', `line', etc.
[Reply] |
I just came up with a new way for choosing baby-names:
... and then just pick one that looks nice. It gives a whole new meaning to the idea of "a pretty name". [Reply] |
I just sent this to some teacher-friends of mine:
[Reply] | |||
It looks like my opinion on the `meta-primitive art' of VisualIDs is vindicated by actual, direct evidence--JP mentioned, in a recent e-mail:


Look familiar? The Museum of Icelandic Sorcery & Witchcraft website (referenced in the URL at the bottom of the second image) says:
... and includes numerous example-glyphs with explanations. [Reply] | |||
One of the things that really struck me about VisualIDs was something that wasn't even discussed in the original essay--something that even seemed to be conspicuously missing after actually working with VisualIDs for even a brief period: there is ever-so-subtle a mention of the `radial' generator, for example, as having `children that could be interpreted as eyes and a mouth', but there was no mention of just how supportive of that `possibility' the visual details end up being--how cleverly (how artfully) they play on the human tendency to see familiar meanings in familiar forms, even when there's really nothing there. Not only do we see `eyes' and a `mouth' inside a Radial glyph invented by the machine, but the `angle-limited edge-children' (using the terms of the shape-language) even appear as `a hairdo' and, when applied recursively in drawing the inner sub-glyphs, Radial's the edge-glyphs often appear to give the `eyes' eyelashes and to give teeth or a `mustache' to a mouth. When Radial and Line combine to form Figure, they resultant glyphs are strongly suggestive of `animals' and `people'.
These were, I think, the first generators that I implemented, and there was quite a punch to it when it started working and, out of nowhere, the machine drew what I could have sworn was a turtle. It's been really interesting to see what sorts of things are suggested by different Radial/Figure productions: some of the icons in my screenshots, I just can't resist calling things like "ninja", "lion", "turtle", "urchin", "tic-tac-toesoldier", "warrior", "spider".... I do wonder what other people would call them. What I've encountered thus far is that, where I see Shapes as `amoebas', my wife sees them as `thought-bubbles'; a friend of mine remarked that `shaving.htm looks hairy', and my wife referenced one file as "the guy with the spiky hair". These glyphs, which are formed by pseudo-randomly applying the shape-grammar, really and honestly don't have any inbuilt meaning, but it seems that they're so readily assigned meaning that we just can't help it (in the same way that it's nearly impossible to avoid the reading of words, seeing sculptures and canals on Mars, and becoming fraught with cognitive dissonance when we try to cite the colour of the next word: "green"), and that's just... fantastic. Accompanying the original essay were also some stylisation options--merely alluded-to by way of example-imagery rather than being outright specified, the list of ideas included glyphs drawn purely with stark black-on-white lines, glyphs that had been colourised and embossed, and glyphs framed by a couple of different types of auxiliary `aqua blob' elements. I have some ideas for how to implement some of the fancier styles, and even some stylistic ideas of my own (Cairo offers some interesting tools like transparency, gradients, clipping, and various options for stroking a path; coordinate-system transformations also apply when stroking a path--I've actually already had some success using that to render `calligraphically'), but I'm really not all that sure of their value: as neat as the `embossing' idea is, I think that I can appreciate it much more from a graphics-geek perspective than I can from an artistic one. As an artist, I find the whole `vaguely-familiar line-drawing' thing to have excellent perceptual characteristics: it's just so easy for us to relate to it--on an even primal level. It's like... an evolution of cave-paintings. Cave-paintings for the digital age? Indeed. Meta-primitive art. As such, the direction in which I'd like to move, as far as glyph-types goes, is toward additional impressionistic or primitive-art-style images mimicking a broader array of fanciful real-world object-types. My wife, for example, asked me:
In fact, under certain circumstances, certain generators do coalesce to produce semblances of `butterflies'..., but it would be nice to be able to tune the system such that `butterflies' could be a distinct feature rather than a rare and happy co-incidence. The definition of a specific `butterfly character' in the shape-grammar would also open-up some additional possibilities for obvious parameters: not adding too much detail (or, perhaps, too many details), because we want to preserve the `primitive art' aspects, but butterfly-wings do have certain universal tendencies that may not be properly captured solely by the use of a generalised system of polar-coordinate renderings of Fourier-series curves. I can immediately imagine extending the visual language to include faces (Radial); people and animals (Figure); butterflies, dragonflies, and faeries; flowers and trees; snowflakes; etc. These should all be fairly straight-forward, since they can all be broken down into coarse geometric or trigonometric primitives with relative ease, and they seem like they should all be fairly successful with many audiences. Myself, I do sort-of like a lot of the Spirals, and I wonder if part of their appeal is perhaps that they are, basically, sort-of vaguely-similar to flowers..., or maybe the appeal of spirals is just part my own idiopathy. These sorts of things can presumably be sorted-out empirically with sufficient number of testers. Even forgoing the fancier render-styles for straight-up
primitive-style line-drawing generators, I am somewhat interested in
expanding the algorithms to include colour (including fills,
background-vs.-foreground contrast...), and the addition of a
Butterfly generator provide a perfect canvas for that. I do think,
however, that one must be careful there: one should take care to avoid
`colour' being the only distinguishing characteristics of
things. I'm particularly sensitive to this because (is this evident
from the graphics on my site?) I have colour-aberrant vision, myself
( Ultimately, it's almost certainly desirable to come up with ways of making the generated VisualID icons basically `fit in' with the rest of the user's desktop-theme, but that seems like a more bigger and more difficult task right now. Of course, I'd be glad to lend an ear to anyone else who's interested in pursuing that goal. [Reply] |
Here's the trick: if you want to find the Levenshtein edit-sequence that leads from one string to another (or, you think, you just want to know which operation occurs at which position in either string), create the complete cost-table, then start at the terminal position and walk backward to the beginning. It's impossible to walk forward from the beginning, because there's too much ambiguity as to which direction the next `step' should take through the maze, but it's actually easy to walk backward: one merely needs to find the direction that either preserves the cost or decrements it by one, with preference given first to cost-decrement and then to diagonal movement (because diagonal cost-preservation is a `keep' operation, and diagonal cost-decrement is a `substitute' operation; horizontal and vertical movement are either insertion or deletion, depending on which string is the source and which is the destination). [Reply] |
All of the shell-script code is generated by the GNU Autotools, so using Automake, Autoconf, and Libtool apparently cut my development-costs by 4.3 months and 2.17 developers (bringing the price down to a much-more-reasonable $69,849). So, use the Autotools--they could save you more than a quarter-million dollars. Also, if you're unemployed for three months, pretend that you were making less money before you lost your job--I know it makes it hurt less for me to pretend that I only lost $14k.... Actually, that $14k did buy me some cool software. [Reply] | |||
Now that I've learned enough Etk to be get hacking, `Mobile VisualIDs' are coming along nicely:
I added a column to
Then I'll see where else it makes sense to add VisualIDs in the phone
UI; the I was able to get the editor running last week, since that (obviously)
didn't require learning anything new aside from loading and using an
OpenMoko toolchain, which
is trivial--my Autoconf While the embedded ARM processor provides enough processing-power to make even real-time editing of VisualIDs reasonably snappy, the `finger-friendliness' is something that I'm going to have to work on: 
For one, I never considered that the monitor might not actually be big enough to hold all of the parameters at once. Of course, the ridiculously-high resolution of the FreeRunner means that quite a lot of data can fit on the screen at once--and even be legible..., but good luck pressing a spinbutton that's 2 millimeters wide. A minor tweak to the GTK+ theme can make the spinbuttons large enough
to be touchable, and putting a Of course, I'd really like to have a click-and-drag, `direct manipulation' mechanism for parameter-modification, which might make the spinbutton issue less relevant. Though, the funny thing about that is: while click-and-drag WYSIWYG editing works great on a bigger screen, I can see how going that way might make things more difficult on a small, finger-oriented screen. So, where the `list of spinbuttons' UI was supposed to be a stopgap on the desktop, maybe it's actually more like the way to go on the FreeRunner. [Reply] | |||
Yes,
Hunh--it's written in Haskell. And it looks pretty short-and-sweet. Maybe I can use srcinst to help me finally get around to learning Haskell. [Reply] | |||
In order to build The thing is, Well, Because, when installing from source, all we need is source-level compatibility, which is a lot easier to get than binary-level compatibility. Open Source FTW. Actually, since I need to build and install several layers (edje ->
evas -> embryo -> ecore ...) of library-packages, maybe I should be
looking at [Reply] | |||
So, I want to add VisualIDs to my FreeRunner. I've actually already built the base code and run-tested it on-device, and verified that it'll be plenty fast enough even without going through a round of optimisations (even the prototype real-time editor GUI seems sufficiently snappy), so I'm on to actually adding a UI-feature to the existing applications--similarly to how the desktop goal was getting VisualIDs implemented in Nautilus. I've been running mainly SHR, and it
looks like the best path to take is to hack on their
After having spent a day or so (spread out over the past week
following receipt of my new, at-least-mostly buzzfixed FreeRunner)
wrapping my head around how contacts-listing elements in a a GLib
Now that it's late enough that it's not even `today' anymore, I think I've got enough of a grip on things to actually write code and verify my understanding..., but it's most definitely time for bed. I always have my doubts about my ability to, after waking from a good night's sleep, remember what the hell I was doing before I went to sleep.... [Reply] |

Apparently, Contrast with Python, where it's That's why that code wasn't working right. The funny thing is..., I was reading over the code, and I said to myself:
I guess I wasn't quite as smart as I didn't remember being, after all. [Reply] |
I just posted my first bugfix-release. More-compact LZMA-compressed archives, along with GPG signatures, are also available in the directory: I've also decided to post the patches that enable VisualIDs in various versions of Nautilus (2.18 thru 2.24): If you're using a Debian-based system, using the Nautilus patches is even easier than usual:
Note that my patches for Nautilus are still somewhat crude at this
point--I haven't learnt to use GConf yet, so the way that you
enable/disable VisualIDs at run-time is to create/remove the
[Reply] |
I've started hacking on an editor-application for the VisualID glyphs: 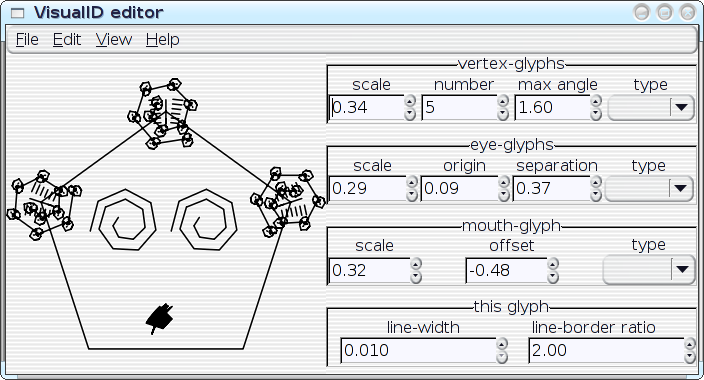
All of the parameters of a VisualID glyph can be adjusted dynamically with real-time feedback. Ultimately, this should become something that end users could utilise to tune their VisualIDs experience to their liking; but something like this can also be extremely useful as an exploratory design-tool for me, to help visualise the implications of choices that that I make in code. I can play with with parameters and see, for example, how well the 2:1 line-to-border ratio actually works in a variety of situations. I can look for trends, and I can even instrument the system to help me spot the trends. Then I can improve the algorithms. In the hands of an end user, the editor could obviously assist on a case-by-case basis (e.g.: `Oh--I don't like that, maybe if I tweak it like this...'), but repeated use of the editor could also actually teach the system to better match the user's aesthetics in future glyph-generation by logging the user's edits to a statistical database. Well, maybe. As it stands right now, the editor... needs some work before I post the code (it's pretty rough, right now), but here are some preliminary screenshots--the following images show a single VisualID producer being reparameterised several different ways: 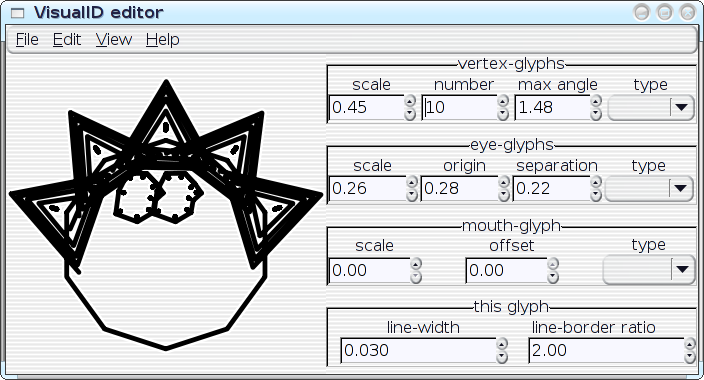
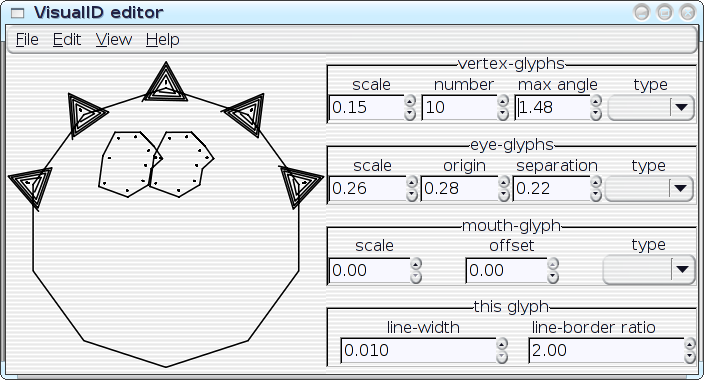
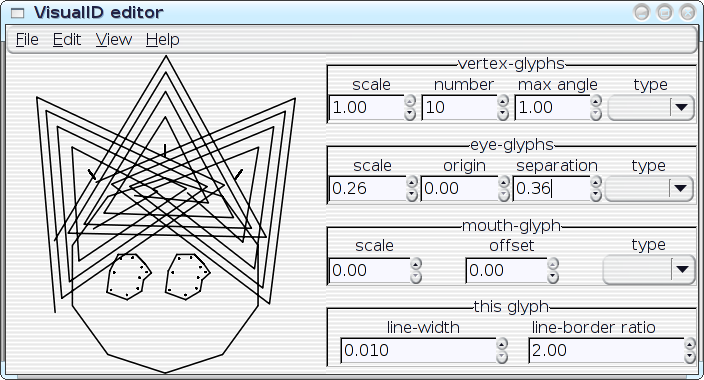
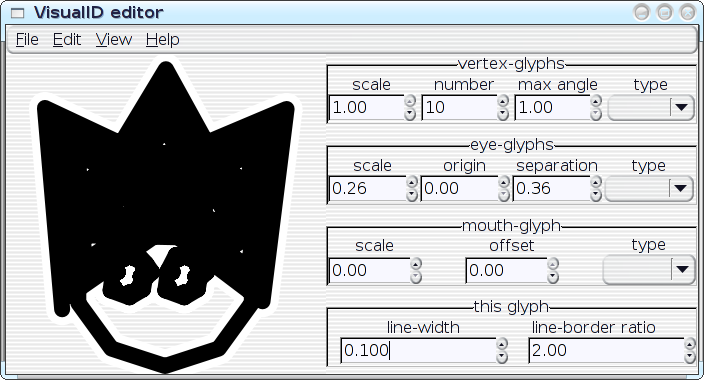
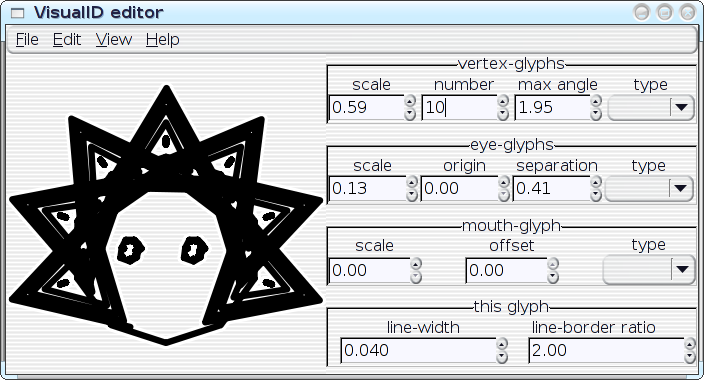
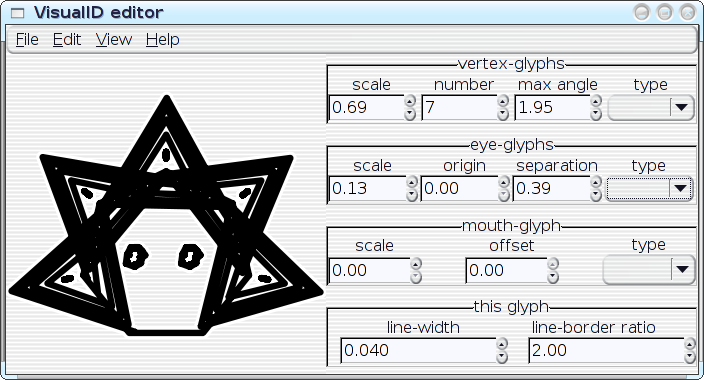
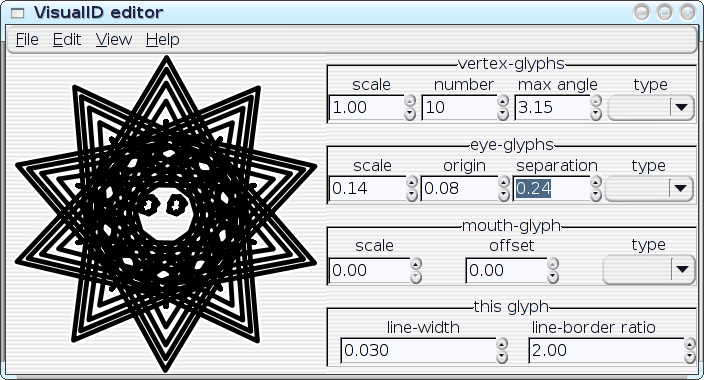
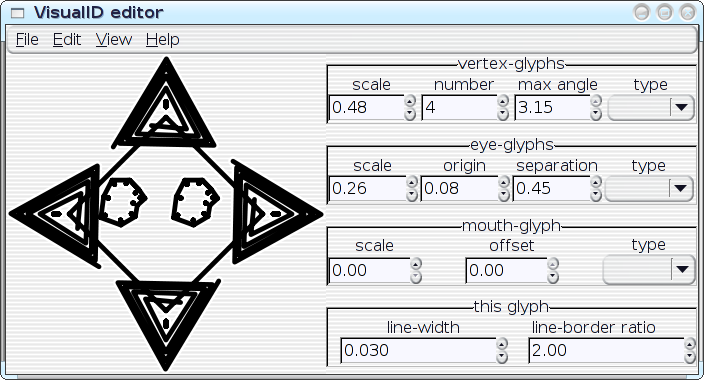
[Reply] |
I've posted `version 0.1' tarballs, along with a Bazaar repository; it's all available at: I've got what I believe are working patches against a couple different versions of Nautilus, copies of which have been given to few people for preliminary feedback. I guess I should work up the gumption to post the nautilus-patches publicly, soon. [Reply] |
Way back in June or July, I had dinner with Chris and Allli, and I got to do a little demo to show-off my VisualIDs-in-Nautilus work as far as it had progressed at that point. Since I'd just started thinking about the problem of identifying similar files in a global context, and was (somewhat stupidly) proud of myself for having come up with a way of seemingly making it easier than I'd initially expected it to be, I raised it in conversation; regrettably, this (along with the talk about my new job) resulted Chris and I marooning Allli in geekspeak.... When I initially read the essay, this part (like so many other parts) looked great (`on paper', as they say?). When I initially dug in as an implementor, this part (like so many other parts) looked more half-baked: deriving icons in a group from the same source made fine sense, but how were the groups to be formed? But then I thought about it some more, and it occurred to me that, since I was keeping a cache of VisualIDs and the names to which they belonged, I could just scan through the cache whenever a new VisualID needed to be generated, see if I could find an appropriately-similar base-ID, and then go from there--this would be where the `longer than 3 characters' part of the matching-algorithm came in. All I would need to do in order to guarantee that this actually worked was to ensure that all of the VisualIDs were generated synchronously, which actually turned out to be easy enough in Nautilus--I ended up hooking into the thumbnail-generation subsystem, which was already synchronous anyway. Chris posited the obvious flaw in this scheme: if one has multiple computers, wouldn't one want the icons to be consistent across all of them? If the consistency breaks down, then doesn't the utility break down? But, unless we have some way of coordinating between the distinct systems, this looks like a hard problem: we can't just use the `ouija-board navigation' technique, we actually have to come up with some sort of consistent algorithm for gleaning some sort of meaningful structure of free-form file-names. Chris didn't think it'd really be that hard of a problem. I'm not convinced that it's anything like easy. It looks like I can actually punt, though--I can say:
And, for the time being, that's what I'm doing: I just added my
So, every aspect of grouping similar icons together is really pretty easy, at least as far as I can see. Where it looks like things get difficult is actually in reverse: guaranteeing that different and unrelated things actually look different, and that things don't end up with similar icons just-by-happenstance. How can that be managed? Can we just assume that the PRNG will make it work out that way? If anyone has any specific thoughts on either issue, I'd love to hear them.... [Reply] |
So far, I've been working with Nautilus 2.20, because that's what
Debian is shipping in Lenny. Mainline Nautilus is actually up to
2.22, and there have been significant changes to the APIs between
2.20 and 2.22. In particular, My patch for Nautilus actually didn't end up being that big, anyway--it basically just changed the default behaviour of the thumbnailer-subsystem. [Reply] |
I've finally started-in on implementing the `similar icons for similar files' logic--so far, I've got the weighted-least-common-substring logic working, which searches through the (ever-growing) cache of VisualIDs for a base-icon. I haven't worked out a system for `mutators' yet, so sufficiently-similar names actually result in the /same/ icon..., but it's getting to be quite a nice demo. Oh--I've also implemented the `around a shape' and `relaxed inside', and `along a path' generators. The presence of these additional options means that all of my icons have changed. Alas--it's no longer generating turtles. It /is/ generating other interesting things, though. I think that, before I call it `done', I'm going to want to add some way for the user to specify constraints for which generators are used, and how the random selection of generators should be weighted. In the mean time, here's another (updated) screenshot: 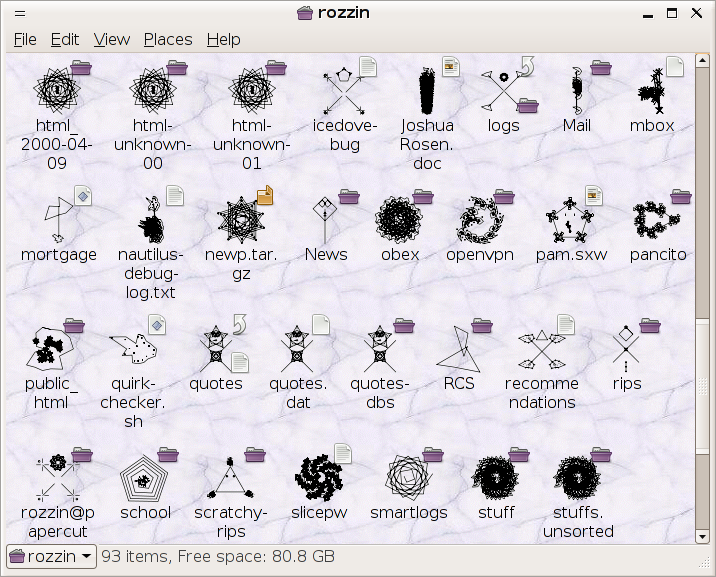
[Reply] |
Yet another interesting thing that just 'falls out' of the way that VisualIDs work: they work just as well for displays of remote data as for local data; and, because of the way that they work, generation is fast for remote files. Here's a screenshot of VisualID-enabled Nautils browsing ftp://ftp.gnu.org/: 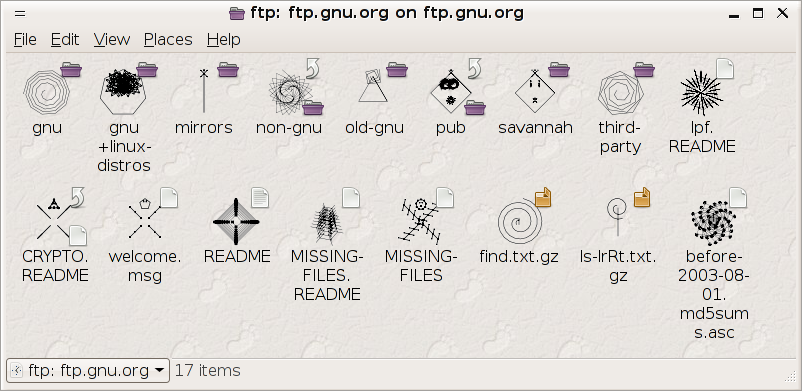
After looking at the previous screenshots, how quickly can you find the README file? VisualIDs are also showing up (as if by magic) in the Nautilus 'Scripts' menu. I can't figure out how to get a screenshot of that.... [Reply] |
It looks like I've actually got it working, automatically generating and caching VisualIDs wherever thumbnails aren't possible. Here are a few random directories on my computer: One bit of behaviour that's different now, and that's bothering me, is that the VisualIDs aren't showing up as WM-icons for Nautilus-windows anymore. I was really getting to like seeing VisualIDs when switching between windows--it's so helpful that I'm tempted to go ahead and hack my window-manager so that I can have VisualIDs to help distinguish between windows of any application (e.g.: the bazillion Epiphany or Emacs windows that I have open). Hm. I had to change the way that I 'reported' VisualIDs in Nautilus in order to get icons to automatically update upon completion of 'thumbnail'-generation (where I was initially hooking into ~/.icons and reporting icon-names that GNOME would resolve to file-paths, now I'm directly reporting file-paths); I wonder if that's what caused this.... Items in Nautilus' "Scripts" menu are still getting VisualIDs, which was (is) another nice side-effect of this. Of course, I still have to add the gconf toggles and similar-IDs-for-related-files (the latter is going to be interesting...), do some general code-cleanup (now that I understand what I'm doing), and maybe see about adding some more generators. I did try implementing 'relaxed inside' and 'scribble', but they had... problems...: 'relaxed inside' just doesn't look right, and 'scribble' is ridiculously inefficient (a pen orbiting a set of gravity-wells? seriously?). I'm pretty sure that I could implement 'scribble' more efficiently by just telling Cairo to run curves between the attractors--should I bother? [Reply] |
I'm trying to put together a demo-collection of the VisualIDs that I've generated, because they look a good deal different than the ones shown in the essay. I'm not sure how to present them all..., but here's a go: I've hacked my GNOME icon-theme so that, in addition to the usual sources, it also pulls icons from a preliminary VisualID-cache. The 'cache' is populated manually, by copying in the VisualIDs that I got by running 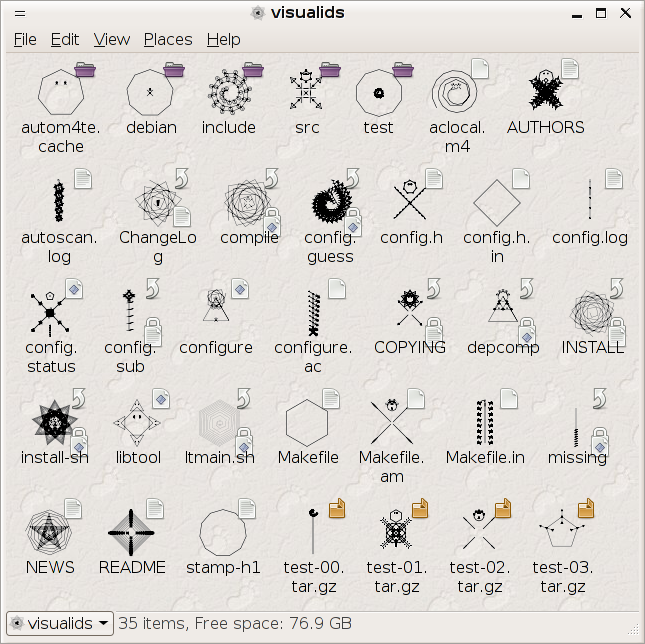
There's that turtle, at the bottom. And take note of the 'README' and 'src' icons--those are classes of files that tend to show up all over the place.... [Reply] |
I got over the initial hurdles of learning Cairo and figuring out basically how I should structure my code to work with it, and now I've got about half of the VisualID `generators' working: radial, spiral, line, figure, and scribble; I'm still working on the `along a path', `around a shape', `relaxed inside', and `symmetry' generators. Oh--Pam has also asked that I add a `butterfly' generator, but I wonder if some butterflies might just fall out of the existing shape-grammar. On a test-run, I was pleasantly surprised to find that the randomly-generated icon for one of my files was... a turtle? [Reply] |
I'm working my way through the more technical parts of the VisualIDs essay, and learning the Cairo API. The essay's really kinda clumsy, when it gets down into the technical bits, but I think I get what it's saying :\ I've got some of the basic VisualID-generation framework in place, now, so the current focus is on learning Cairo. [Reply] |
I started hacking on Nautilus a couple of days ago with the intent of adding support for VisualIDs, and I've already been successful in implementing the Nautilus-side requirements. At this point, I'm using a store of pregenerated VisualID icons, and a not-very-good hashing-algorithm that maps files to VisualIDs. Now I just need to: - develop a VisualID-generation library using the algorithms outlined in the essay - make Nautilus use the library instead of my static icon-store - add some GConf toggles so that Nautilus VisualID subsystem can be enabled/disabled during runtime Here's a screenshot of a directory-view in Nautilus using VisualIDs: files are all uniquely identified by VisualIDs; the file's type is indicated by an auxiliary `emblem' attached to periphery of the main icon, because file-type is still valuable information--it's just not quite /as/ valuable as a quick/easy/obvious `wether this is the file that you want' indicator (i.e.: the VisualID). If a file is actually a symbolic link, that's also indicated by an `elsewhere-pointing arrow' emblem. You'll notice a few different file-types and 1 symbolic link, here: 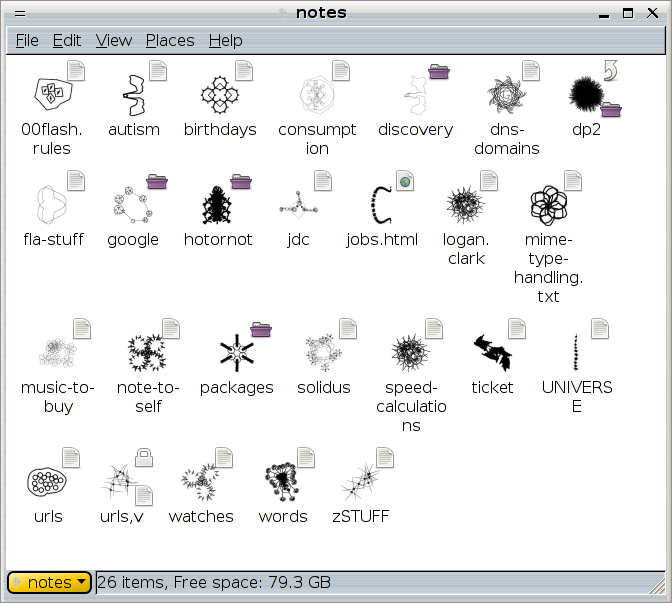
Now, here's another screenshot: this one mixes in a few more more file-types, including some that /don't/ use VisualIDs because they're thumbnailable: I have it setup so that, by default, `graphical' files (image-files and video-files, for example) use a thumbnail version of their action content for their icons, and any files that can't be thumbnailed (including types like directories, text-files, audio-files, etc.) use VisualIDs. You'll notice that there are several image-files and 1 video-file (all of which use thumbnail-views for their icons), a few audio-files, a couple of HTML-files, and a shell script, with all of the files which would traditionally all have the exact same icon now having unique VisualIDs: ![[screenshot]](/~rozzin/VisualIDs-02.png)
This screenshot may be a little confusing, because I'm also using some auxiliary `visual tagging' facilities that Nautilus provides: ![[screenshot]](/~rozzin/VisualIDs-00.png)
While either VisualIDs or thumbnails are used as /default/ icons, and a file-type emblem is also added by default, individual files can also have custom emblems added by the user, and they can also have custom icons set by the user, and setting a custom icon does away with the default (type-indicating) eblem; this is why `collections' and `contacts' don't have any emblems (as the user who set the custom icons, I know that they're directories and don't need any auxiliary `what is it' info--I just need to be able to find them quickly); `photovideo', `graphics', and `html' are also directories with custom icons, but I (as a user) have also added custom emblems to them. I've also added custom emblems to `contracting', `finances', `cvs', `dp2', and a few other directories, but not set custom icons--this is especially useful in combination with Nautilus' `sort by emblems' feature, which allows me to (for example) group all of the money-related objects together. [Reply] |